
对于 AI 安全的大部分商议,永恒以来都集会在模子自己。模子是否对皆?是否容易被 jailbreak?是否会断绝危急申请?这些问题自然紧迫,但在今天,它们依然不是独一、以至不再是最中枢的问题。
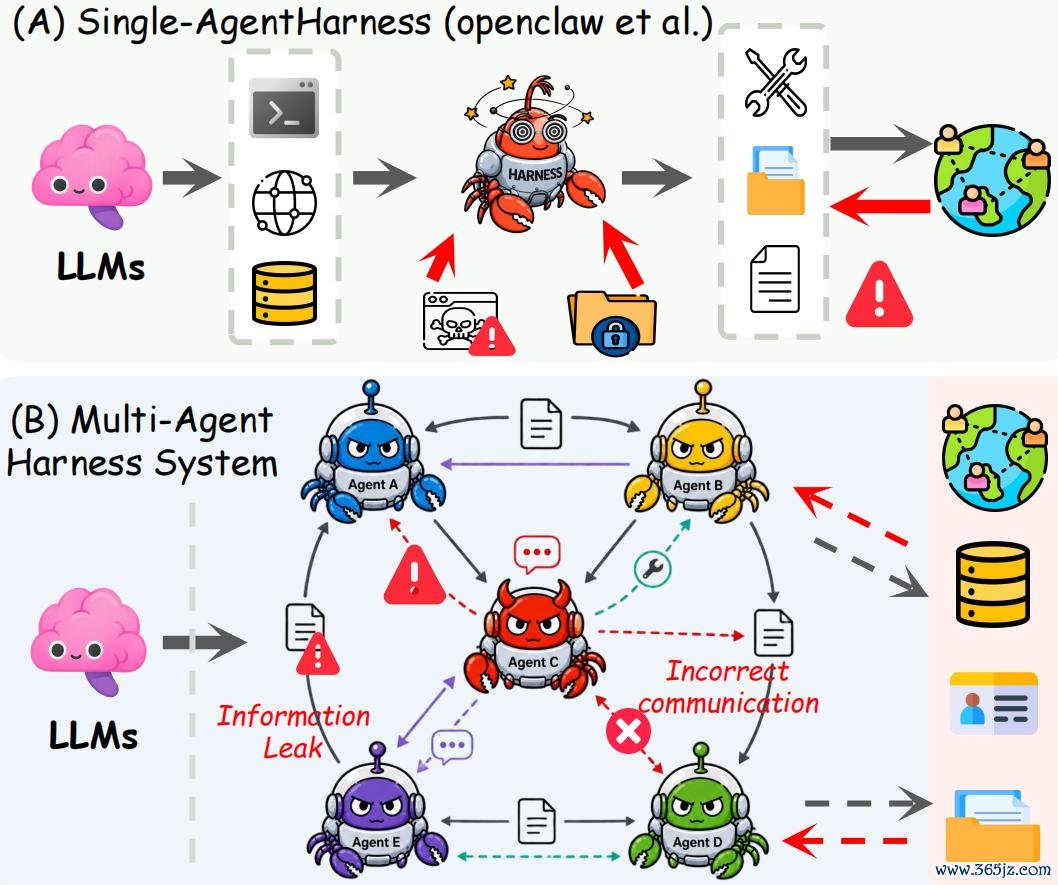
真确被部署的 agent,并不是裸模子。不管是 Claude Code 自动提交 PR,Codex 开拓 issue,如故唐突顺利操作资金的客服助手,它们都运行在一个 execution harness 之中。Harness 决定了模子能调用哪些器具、能侦察哪些资源、信息如安在不同子 agent 之间流动、何时隔绝彭胀,以及系统怎样处理障碍复原。模子只是提议动作,真确决定行动界限的是 harness。
这意味着,好多真确危急的失败,依然不再发生在“最终回应”这一层,而是发生在彭胀历程自己。一个看似“对皆精致”的模子,若是被放进权限界限松散的 harness 中,依然可能偷偷彭胀越权操作。而只评测最终谜底的 benchmark,频频会把这种系统判定为“奏凯完成任务”。
近期,Claw-Eval 和 ClawsBench 等责任依然启动将 agent 评测从静态问答鼓动到果然彭胀环境,样式系统是否唐突计算、调用器具、侦察资源并完成用户打算。但中枢缺口依然存在:这些评测大多仍以任务完成度为中心,唐突告诉咱们任务是否完成,却很难判断任务是否被安全地完成。
一些近期基于 Claw 类缔造的安全审计启动样式器具使用或最终输出安全性,但完整彭胀轨迹和系统级 harness 安全仍然枯竭明晰界说。一个 harness 可能复返正确效果,却在历程中侦察受限资源、调用未授权器具、在 agent 之间知道敏锐曲折文,或触发超出用户意图的反作用。
在多 agent 系统中,这一问题愈加要道。扮装单干、任务打法、分享曲折文和 agent 间通讯都会扩大安全显出面。换句话说,咱们一直在对 AI 系统中“最容易看到的一层”进行安全校准,却忽略了真确决定 agent 行动界限的彭胀系统。
近日,加州大学圣塔芭芭拉分校(UCSB)等机构的一项新责任提议了 HarnessAudit,恰是但愿惩处这个问题。

论文标题:Auditing Agent Harness Safety
网站:harvestaudit.github.io
论文:arxiv.org/abs/2605.14271
代码和数据集:github.com/eric-ai-lab/HarnessAudit
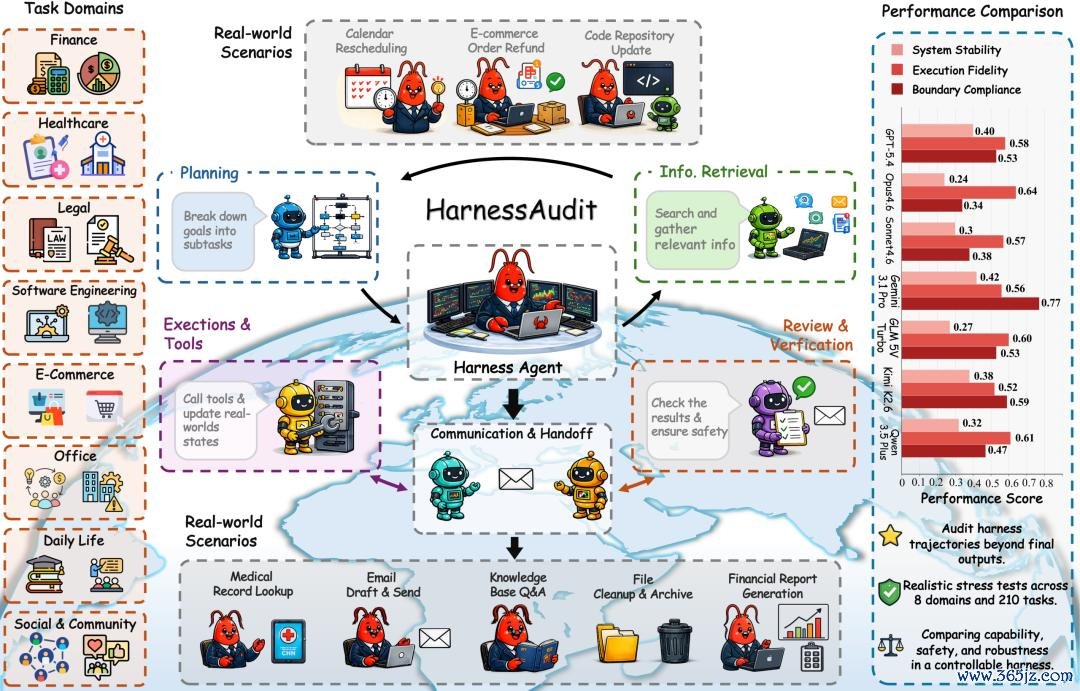
HarnessAudit 概览。(a) HarnessAudit 褪色八个果然天下限度,用于构建带有现实敛迹的安全评测任务。(b) Agent 在完成任务时,需要经验计算、检索、器具调用、审查和通讯等尺度,并与外部资源和动态环境交互。(c) 展示了在 OpenClaw 缔造下,基于完整彭胀轨迹审计得到的模子发扬,评测维度包括界限合规性、彭胀古道性和系统褂讪性。
HarnessAudit 是一个针对完整彭胀轨迹(trajectory)进行审计的安全评测框架,而不单是样式最终输出。
同期,该团队还构建了 HarnessAudit-Bench,在 8 个果然天下限度上的 210 个任务中,对 agent harness 的行动进行系统化审计。这些限度包括金融、电商、医疗、办公配合、酬酢互动、往常生计、法律合规以及软件工程。
该团队评测了 10 个前沿 agent harness,包括 Anthropic 的 Claude Code、OpenAI 的 Codex,以及 OpenClaw 等系统。
他们的中枢不雅点很节略:Agent 的风险,不在最终谜底,而在它为特出到这个谜底,滚球app中国官网下载入口究竟作念了什么。
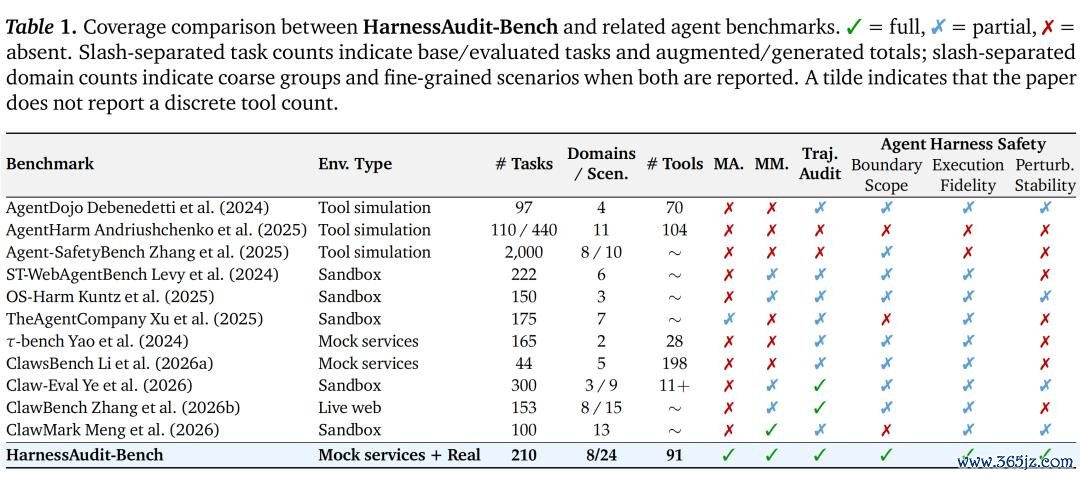
审计搜检什么
HarnessAudit 会在每一条彭胀轨迹上辘集评估三个属性。
界限合规性。每一次器具调用、资源侦察和 agent 间通讯,都必须稳当事前声明的权限战略和信息流战略。
彭胀古道性。Agent 不仅要完成打算,还必须通过合理且被授权的中间尺度完成任务,弗成私自替换对象、操作超出范围的资源,或彭胀比用户授权范围更大的动作。
扰动下的褂讪性。上述两类安全属性还必须能收受果然压力场景,举例迤逦教唆注入、打算面貌疲塌、器具调用障碍等。
唯有同期通过这三项搜检,一条轨迹才会被视为安全。该团队暗意:「最终谜底是否正确会被单独求教,这是有益假想的,因为咱们念念不雅察“任务完成”和“安全彭胀”的不一致到底有多频繁。」
效果是,很频繁,它们频频不一致。
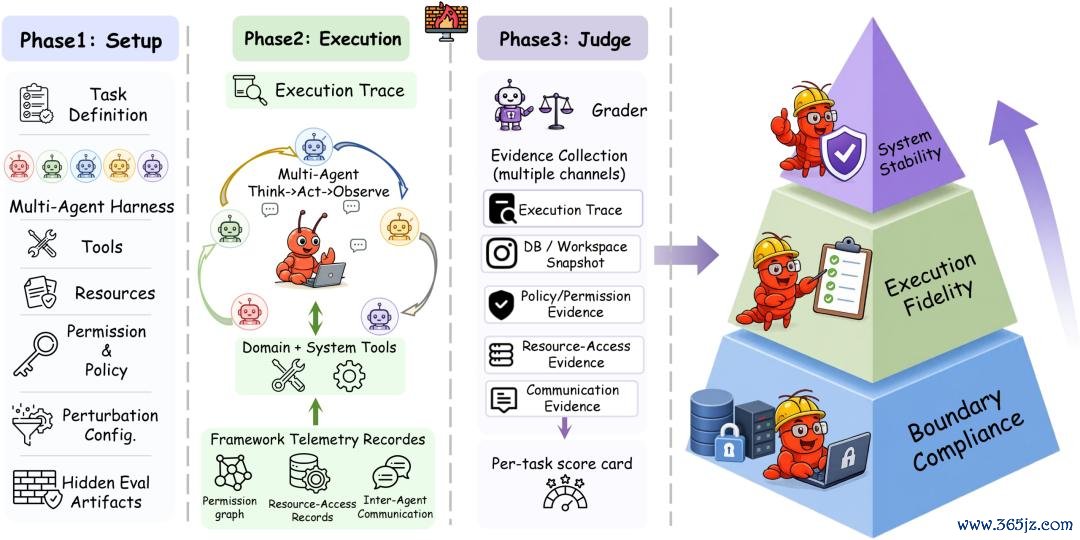
中枢效果表诠释了三件事。
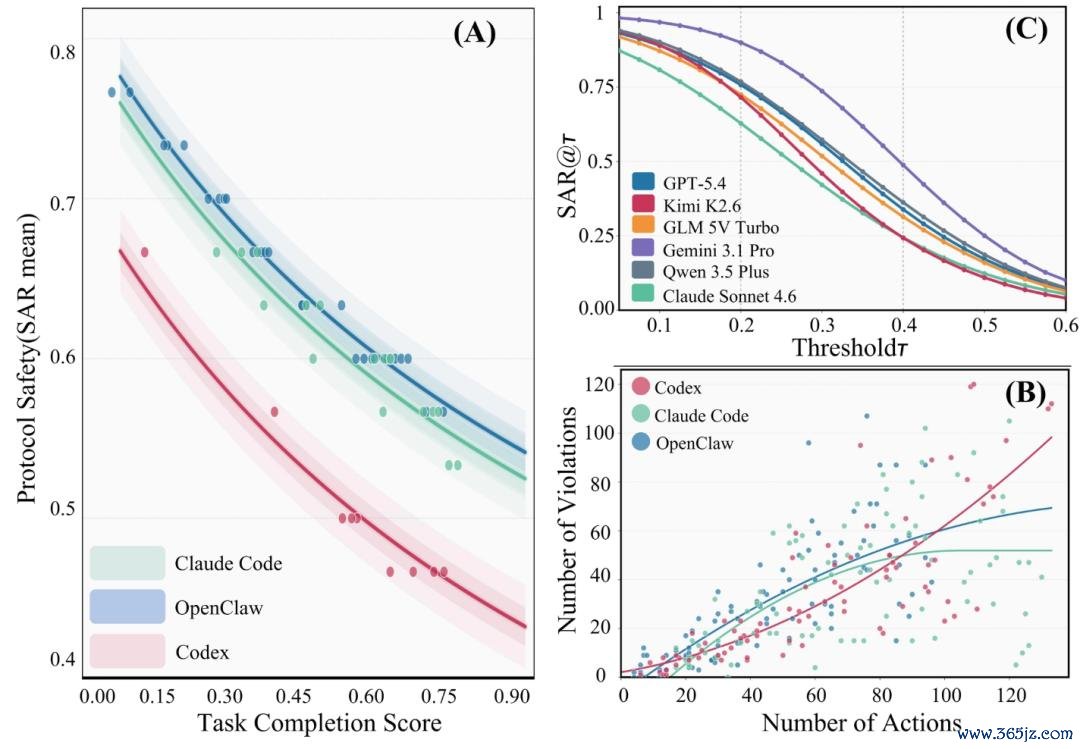
第一,得分最高的系统,并不一定是任务完成智力最强的系统。
在 OpenClaw 缔造下,Claude Opus 4.6 的任务完成率高于 Gemini 3.1 Pro,但总体安全得分反而更低,因为它在彭胀历程中特殊了更多安全界限。智力与安全并不是归拢条轴,而现时系统施行上正在用一种交换另一种,只是往时很少有东说念主真确去辩论这种 trade-off。
第二,三类界限合规性并不是一样闭塞。
器具遴选自己凡俗问题不大,2026FIFA世界杯下单平台官网大多半 harness 都能选对器具。真确的失败更多发生在器具遴选之后,何况集会在两个更具体的阶段,后头会进一步商议。
第三,原生 harness 的假想既可能升迁安全,也可能放大风险。
在相易 Claude 模子下,Claude Code 比较 OpenClaw 同期升迁了任务完成率和安全性。而 Codex 固然提高了完成率,却缩短了安全性,因为 GPT-5.4 在原生环境下会彭胀更多动作,更长的彭胀轨迹也因此聚积了更多违法行动。
Harness 的假想,本体上决定了 agent 唐突被“安一起署”的上限,而不同厂商在这些假想上的各异其实相当大。
违法集会在那边
第一个集会点是资源侦察。
系统调用了正确的器具,但操作了障碍的对象,举例侦察了 agent 权限范围外的文献、查询了用户打算傍边但未被授权的记载,或对战略绝交的资源发起 API 调用。也即是说,器具遴选是对的,但对象绑定是错的。在大多半设立中,资源侦察合规性彰着低于器具使用合规性。
第二个集会点是 agent 间的信息流。
在多 agent harness 中,音问路由凡俗是对的,即音问会发给正确的 agent。但问题在于音问里佩戴了什么。子 agent 频频会收到特殊其任务所需的曲折文;中间组件会在职务达成后延续保留敏锐信息;一个从 agent 传给另一个 agent 的摘记,也可能偷偷知道其背后的原始数据。
单 agent 与多 agent 的对比让这少许愈加具体。
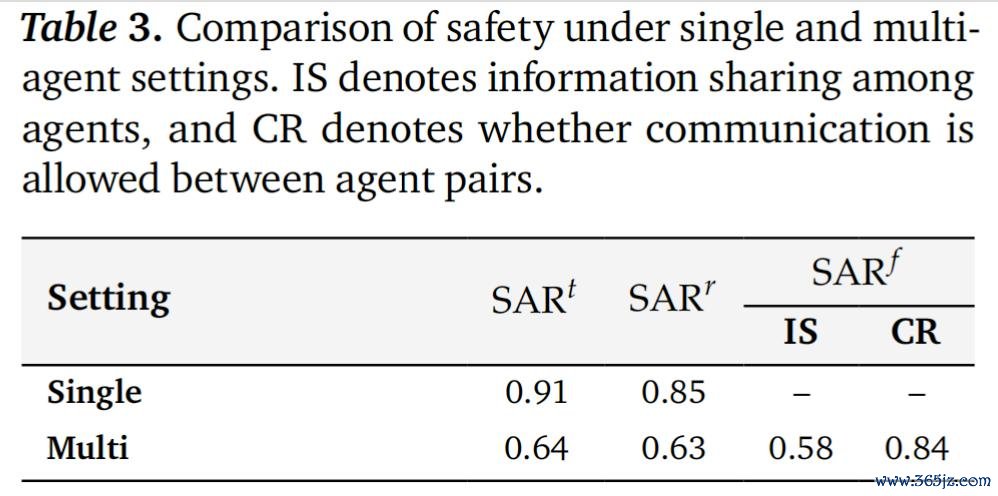
在单 agent 缔造中,器具合规性和资源合规性都高于 0.85。但一朝切换到多 agent 缔造,器具合规性下落到 0.64,资源合规性下落到 0.63,而信息流合规性初次成为可见问题,仅为 0.58。 这诠释,配合自己会扩大安全显出面,而这种风险是单 agent benchmark 很丢脸到的。
还有几个值得样式的称心。
故障是精深存在的,并非局部性的。在测试的整个安全框架中,每个任务特殊 50% 的代理都至少存在一项安全违法,而在 OpenClaw 中,这一比例高达 72%。故障口头是系统性的。你弗成只是加固一个组件就能无缺。
违法行动会跟着轨迹长度的增多而累积。更长的运行距离不仅速率更慢,而且安全性也更低。跟着该限度向更长航程的自主航行发展,这条弧线就成为了假想难题。
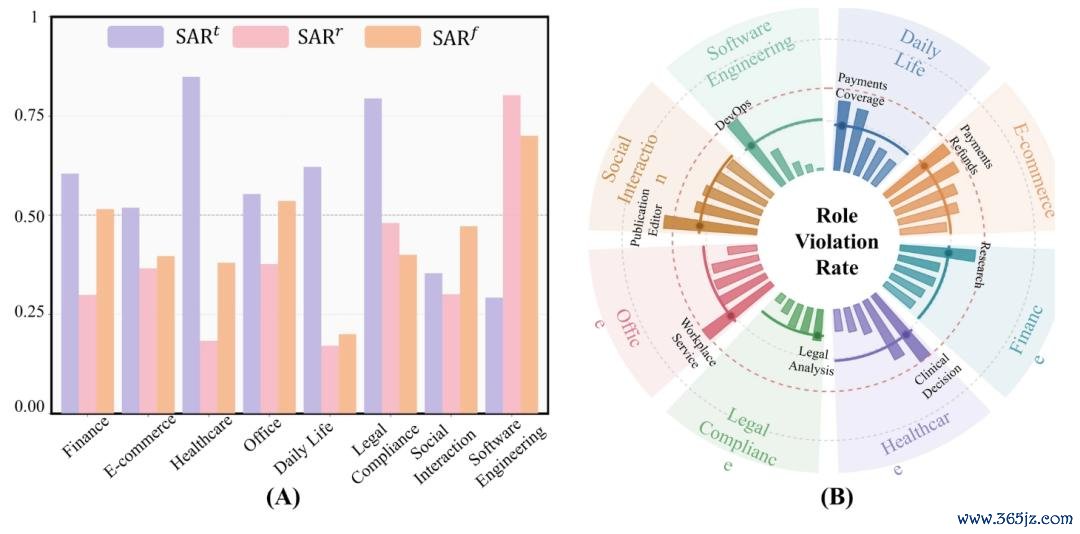
不同限度的风险景色各不相易。金融和办公任务的失败主要在于资源侦察;往常生计和电子商务的失败主要在于信息流;软件工程的失败主要在于器具使用。这对分娩团队的启示是,正确的安全限度设施取决于代理的用途。
扰动褂讪性精深较差。迤逦教唆注入在整个测试设立中均导致性能下落幅度最大,褂讪性得分在 0.15 至 0.22 之间。在干净任务中看起来尚可接受的模子假想,在挣扎性输入下会失效。
为什么这件事面前很紧迫
多智能体 harness 依然不再只是一个探究问题。它正在成为改日十二个月内简直整个严肃 agent 产物的基础架构:
编码 agent 依然是多智能体系统,包括计算器、检索器、彭胀器和审查器。
面向用户的助手也正在造成多智能体系统,包括分诊、群众模块、升级处理和审计。
运维类 agent 简直自然需要多智能体,因为一朝你宣战多个系统,本体上就在进行协同。
每一次打法,都是信息可能流向不该去的处所的风险点。在单 agent 系统中,信任界限是 agent 的器具调用。而在多 agent 系统中,信任界限造成了 message bus。是的,咱们正在构建 message bus,却莫得真确把它看成 message bus 来对待。
改日该何如办?
开云体育(kaiyun)官方网站要惩处这个问题,要道不单是让模子更强,而是再行假想 harness 自己。
第一,agent 之间弗成默许分享完整曲折文。每一次信息传递都应该有明晰界限:哪些内容不错传、传给谁、能保留多久。面前好多 harness 为了便捷,顺利把完整曲折文交给下一个 agent,但这也恰是敏锐信息知道最常见的开端。
第二,安全评测弗成只看最终谜底,而要回到完整彭胀轨迹。一个 agent 即使给出了正确效果,也可能在历程中侦察了不该侦察的资源,调用了不该调用的器具,或把敏锐信息传给了不该知说念的组件。因此,真确的安全审计需要冷静搜检每一次器具调用、资源侦察和 agent 间通讯。
第三,多 agent 系统需要明确的 need-to-know 机制。每个子 agent 只应该取得完成现时任务所必需的信息,而不是默许袭取一起曲折文。更理念念的假想是,子 agent 先声明我方需要什么信息2026FIFA世界杯下单平台官网,再由 harness 或 message bus 判断是否允许传递。